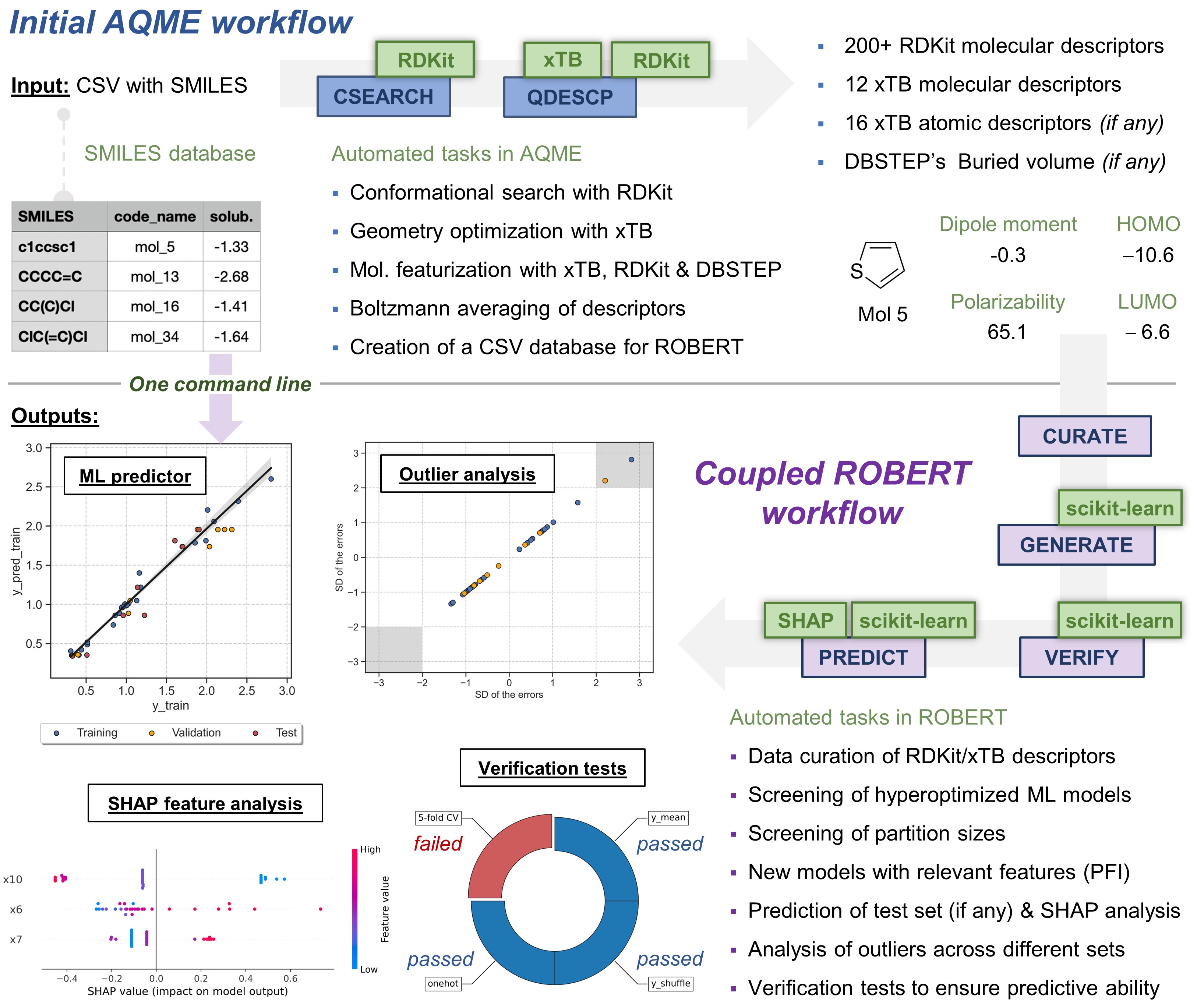
Full workflow from SMILES
Overview
Reproducibility warning
Warning
Update to AQME v1.6.0 or higher to obtain fully reproducible results! You can do it with pip install aqme --upgrade.
Otherwise, it may not be possible to exactly reproduce the results due to subtle differences in the
generated xTB descriptors (0.1% changes in most cases).
Required inputs
solubility_short.csv: CSV file with SMILES to generate descriptors that will be used as the training and validation sets. The full CSV file can be found in the Examples folder of the ROBERT repository or downloaded here:

code_name |
smiles |
solubility |
|---|---|---|
mol_100 |
CC(C)c1ccccc1 |
-3.27 |
mol_1000 |
Cc1ccc(O)cc1 |
-0.73 |
... |
||
mol_1089 |
ClCC |
-1.06 |
mol_109 |
CC(C)C |
-2.55 |
The CSV database contains the following columns:
code_name: compound names.smiles: SMILES strings of the compounds.solubility: solubility of the compounds.
Required packages
Openbabel: Install Openbabel with conda-forge:
conda install -y -c conda-forge openbabel=3.1.1
AQME: Install (or update) AQME with conda-forge (or follow the instructions from their ReadtheDocs):
pip install aqme
xTB: Install xTB with conda-forge (or follow the instructions from their documentation):
conda install -y -c conda-forge xtb
Warning
Due to an update in the libgfortran library, xTB and CREST may encounter issues during optimizations. If you plan to use them, please make sure to run the following command after installing them:
conda install conda-forge::libgfortran=14.2.0
Executing the job
Instructions:
Install the programs specified in Required packages.
Download the solubility_short.csv file specified in Required inputs.
Go to the folder containing the CSV file in your terminal (using the "cd" command, i.e.
cd C:/Users/test_robert).Activate the conda environment where ROBERT was installed (
conda activate robert).Run the following command line:
python -m robert --aqme --y solubility --csv_name solubility_short.csv
Options used:
--aqme: Calls the AQME module to convert SMILES into RDKit and xTB descriptors, retrieving a new CSV database.--y solubility: Name of the column containing the response y values.--csv_name solubility_short.csv: CSV with the SMILES strings.
By default, the workflow sets:
--ignore "[code_name]"(variables ignored in the model)--discard "[smiles]"(variables discarded after descriptor generation)--names code_name(name of the column containing the names of the datapoints)
Execution time and versions
Time: ~1.5 min
System: 4 processors (Intel Xeon Ice Lake 8352Y) using 8.0 GB RAM memory
ROBERT version: 1.2.0
scikit-learn-intelex version: 2024.5.0
AQME version: 1.6.1
xTB version: 6.6.1
Results
Initial AQME workflow
The workflow starts with a CSEARCH-RDKit conformer sampling (using RDKit by default, although CREST is also available if
--csearch_keywords "--program crest"is added).Then, QDESCP is used to generate more than 200 RDKit and xTB Boltzmann-averaged molecular descriptors (using xTB geometry optimizations and different single-point calculations).
A CSV file called AQME-ROBERT_solubility_short.csv should be created in the folder where ROBERT was executed. The CSV
file can be downloaded here: ![]()
Following ROBERT workflow
A PDF file called ROBERT_report.pdf should be created in the folder where ROBERT was executed. The PDF
file can be visualized here: ![]()
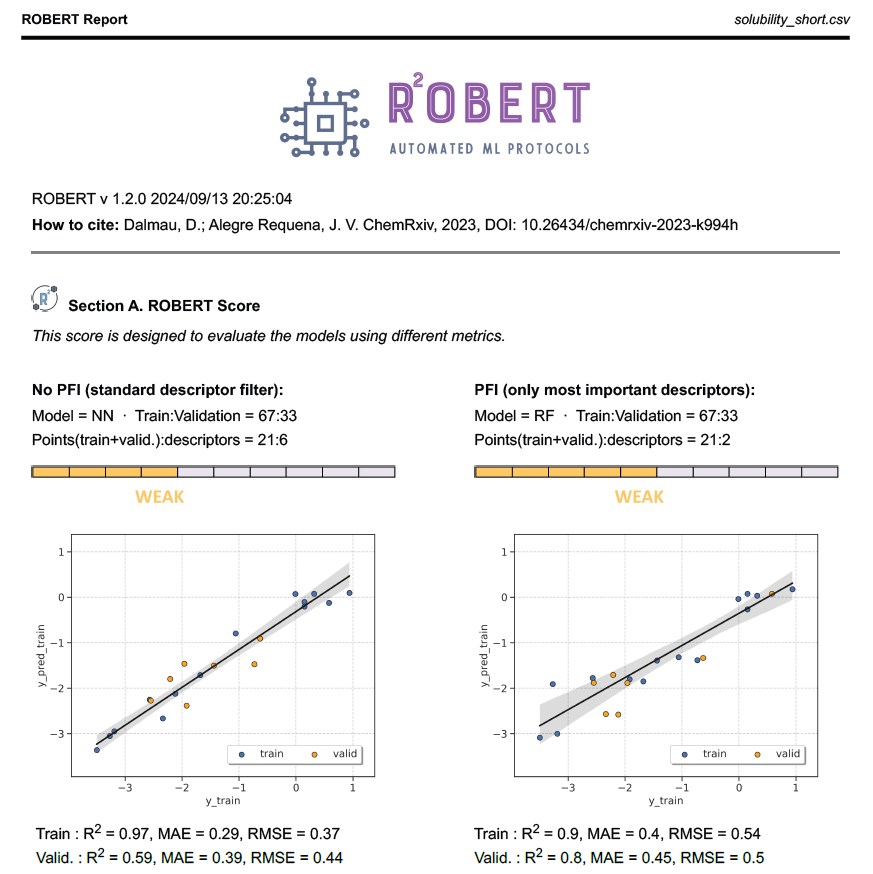
The PDF report contains all the results of the workflow. In this case, two Random Forest (RF) models with 70% training sizes were the optimal models found from:
Four different models (Gradient Boosting GB, MultiVariate Linear MVL, Neural Network NN, Random Forest RF)
Two different partition sizes (60%, 70%)
The first part of the PDF file is shown below as a preview: